Getting started
AILL Research
Real Applied AI benchmarks, persistent internal memory, native text output, and public-safe research artifacts.
Elena AILL is the main research project. The current active runtime path is SenzaAdam Big Brain + Clean Speak: Big Brain provides persistent internal memory and context, while Clean Speak is the controlled text output layer.
Earlier SenzaAdam Brain + SPEAK-NEW work remains documented as validated lineage. GLIA, Hebbian, synaptic, and dense AILL experiments remain preserved as research history, not as the current public runtime claim.
Elena AILL does not grow only by becoming a bigger Transformer. The current active path focuses on local memory updates, bounded active cells, cold reload validation, anti-forgetting, and internal memory recall without external RAG or vector database runtime.
Research evidence only
Real PNG charts only
Current path: Big Brain + Clean Speak
Reads, writes, codes, documents
◆
10M parameter milestone validated — this preview is anchored to validated benchmark evidence and keeps the demo behind the existing quality gate.
What is Elena AILL
Elena AILL is the main research project and the public page is written as an AILL Research status surface plus an Applied AI benchmarks release. Every public claim is tied to benchmark evidence, report language, or PNG artifacts already generated in the workflow.
The system is built from scratch and documented conservatively: the overview introduces the runtime, while the architecture and public-surface pages explain lineage, constraints, and release boundaries in more detail.
Current active runtime
The active project path is test-modello/aill_originale. Big Brain is the persistent internal memory and context backend; Clean Speak is the final controlled text output layer. Big Brain is not allowed to generate the final answer directly.
SPEAK-NEW remains in the documentation for continuity, SEO, and research traceability. It is preserved as earlier validated memory-to-language lineage behind the current Clean Speak direction, not as the current runtime wording.
Current
SenzaAdam Big Brain
Persistent internal memory based on local cells, synaptic associations, bounded active paths, cold reload checks, and anti-forgetting validation.
Current
Clean Speak
The output layer that turns internal memory and context into controlled Italian text and decides when to answer or ask for clarification.
Lineage
SPEAK-NEW lineage
Earlier validated output and runtime lineage preserved for continuity. It remains documented, but the current website formula is Big Brain + Clean Speak.
Research-only
Archived and legacy paths
Older dense AILL, archived branches, and external demo or tool paths remain preserved as historical research, not as active runtime.
Validated Applied AI benchmarks for the 10M persistent-memory milestone
This benchmark bar is intentionally compact but specific. It summarizes the verified 10M SenzaAdam result using the same measured fields that appear in the public reporting workflow: learned facts, created cells, reused cells, recall, anti-forgetting, active path size, and persistent brain artifact size.
That matters for Applied AI indexing because the page does not ask the reader to trust a vague claim such as memory improved or performance scaled. It exposes the exact benchmark vocabulary used to describe what changed, what remained stable, and what the public package can defend.
10-second summary
What Elena AILL has achieved so far — in 10 seconds
Elena AILL is an independent AI research project built from scratch in PyTorch, focused on persistent internal memory, bounded context, and modular training.
Developed and tested on consumer hardware, including an NVIDIA RTX 4060 Ti 16GB.
1M + 10M completed
10,833,323 learned facts validated.
Memory signals stayed strong
recall_score 0.9883 · anti_forgetting_score 1.0000
Big Brain + Clean Speak
SenzaAdam Big Brain + Clean Speak is the active public formula, with earlier research lines preserved elsewhere in the documentation.
100M deferred, public scope controlled
100M was deferred, not failed, and the release scope stays focused on evidence, documentation, and validated artifacts.
Research status release: validated Applied AI benchmarks, benchmark metrics, and real generated PNG artifacts.
Core modules
| Module | Role | Status |
|---|---|---|
| SenzaAdam Big Brain | Persistent internal memory and context layer based on local cells, bounded active paths, cold reload checks, and anti-forgetting validation. | Active |
| Clean Speak | The output layer that turns internal Big Brain context into controlled Italian text and decides when to answer or ask for clarification. | Active |
| SPEAK-NEW lineage | Earlier validated output lineage preserved for continuity. It remains documented, but the current website formula is Big Brain + Clean Speak. | Active |
| Archived and legacy paths | Dense AILL history, older branches, and archived runtime experiments are preserved as research history, not active runtime. | Archive |
Design constraints
- No global backpropagation. All weight updates are computed from local cell activity. From Phase 41 onwards, the entire training pipeline uses local rules only.
- No transformer attention. Context and long-range dependencies are handled through the Big Brain memory layer and native cell connections.
- No external model dependencies. No third-party weights are loaded at runtime. No cloud inference API is called at any stage.
- No borrowed architecture. Elena AILL is not a derivative of GPT, LLaMA, Mistral, or any other published model family.
- Identity stability. Self-reference outputs must remain consistent across restarts and checkpoint loads. First validated in Phase 16b; stable since.
Current status
As of June 2026, training is in Stage 7 (Phase 45+). The 10M parameter milestone is validated and stable. Architecture documentation, benchmark results, and public artifacts are accessible and aligned with the repository evidence.
⚠
Demo access is not yet open. The public demo is gated behind the Stage 7 benchmark quality check. This page will be updated when that gate passes. Do not assume demo availability based on milestone progress alone.
Architecture
System design
Elena AILL uses no gradient descent, no attention mechanisms, and no pre-trained external weights. The full system is composed of four native modules developed and validated independently.
Current validated runtime architecture and public evidence boundary
Elena AILL works through its native runtime: SenzaAdam Big Brain + Clean Speak.
The project was not started as a fine-tuned commercial model or an external LLM wrapper. Elena AILL was implemented from scratch in PyTorch, with custom research modules developed and tested on local hardware, including an RTX 4060 Ti 16GB.
The public package publishes verified research data, benchmark reports, architecture history, and real PNG charts only. It does not advertise public chat, upload, SaaS access, or a live web demo.
This boundary is deliberate and useful for accuracy. The page can be read as an AILL Research document about persistent memory, Applied AI benchmarks, and modular runtime validation without pretending to be something the project is not claiming.
Main project
Dense history preserved, validated path clarified
Earlier dense AILL models remain preserved as research history while the active public path is SenzaAdam Big Brain + Clean Speak, backed by persistent internal memory and source-traced benchmark evidence.
Modular training
Not fine-tuning
This is modular training, memory ingestion, and persistent brain updates rather than a single monolithic fine-tuning story.
Public boundary
Evidence before product surface
The website surfaces benchmark evidence first. The interactive demo stays private until the Stage 7 writer is ready.
Readers should read this architecture section as the shortest honest summary of the live public state: Elena AILL is the main research project, SenzaAdam Big Brain stores and recalls persistent internal memory and context, Clean Speak turns that context into controlled written output, and the public site documents evidence before claims.
Research Lineage
Elena AILL remains the main project, while the public site distinguishes research lineage from active runtime. Earlier dense AILL history remains preserved, GLIA stays as a research track, and the current public formula centers on SenzaAdam Big Brain + Clean Speak.
This distinction is central to how the project should be indexed and understood. In practical Applied AI terms, the site separates preserved historical work, currently validated runtime components, and the public evidence boundary that limits what can honestly be claimed today.
Elena AILL Main Project
├── Dense AILL Research History
│ ├── earlier dense models and checkpoints preserved
│ ├── legacy benchmark references kept
│ └── not the current public runtime path
│
├── GLIA Research Track
│ ├── memory and routing validation
│ ├── internal recall and QA from memory
│ └── preserved benchmark evidence
│
├── SenzaAdam Big Brain
│ ├── active persistent-memory and context module
│ ├── no Adam optimizer state
│ ├── no global backward on the active memory path
│ └── verified 10M benchmark result
│
├── Clean Speak
│ ├── current text output layer
│ └── final response layer for the active public formula
│
├── SPEAK-NEW
│ └── documented historical memory-to-language lineage
│
└── Stage 7
└── integration, packaging, and release scope
Main project
Elena AILL stays the top-level project
Dense AILL history remains public research context, but it is no longer the active validated public runtime path.
GLIA
GLIA research track
GLIA remains preserved as technical history and benchmark evidence, not as the current public serving runtime.
Persistent memory
SenzaAdam Big Brain
The active public research module stores and recalls learned facts as internal memory and context without Adam optimizer state or global backward in the active path.
Output layer
Clean Speak
Clean Speak turns internal Big Brain context into controlled Italian written answers while keeping benchmark accountability visible. SPEAK-NEW remains documented lineage.
Validation
Stage 2-6 public evidence
The current public package publishes only validated benchmark stages, reports, and real PNG charts.
Release gate
Stage 7 before public demo
The current focus is to improve written output quality, coding reliability, and document consistency without weakening the memory-grounded runtime.
GLIA Research Track
GLIA is a preserved Elena AILL research track for memory and routing validation. It was used to explore entity recall, internal memory recall, routing, QA from memory, and interference-resistant recall. GLIA is not the current public runtime, but it helped validate ideas that informed the current Elena AILL direction: persistent memory, bounded routing, and modular architecture.
GLIA remains in the project because it explains where part of the current vocabulary came from. The public discussion of routing, internal recall, entity recall, and interference resistance did not appear suddenly with the 10M SenzaAdam result; it was shaped by earlier isolated validation work.
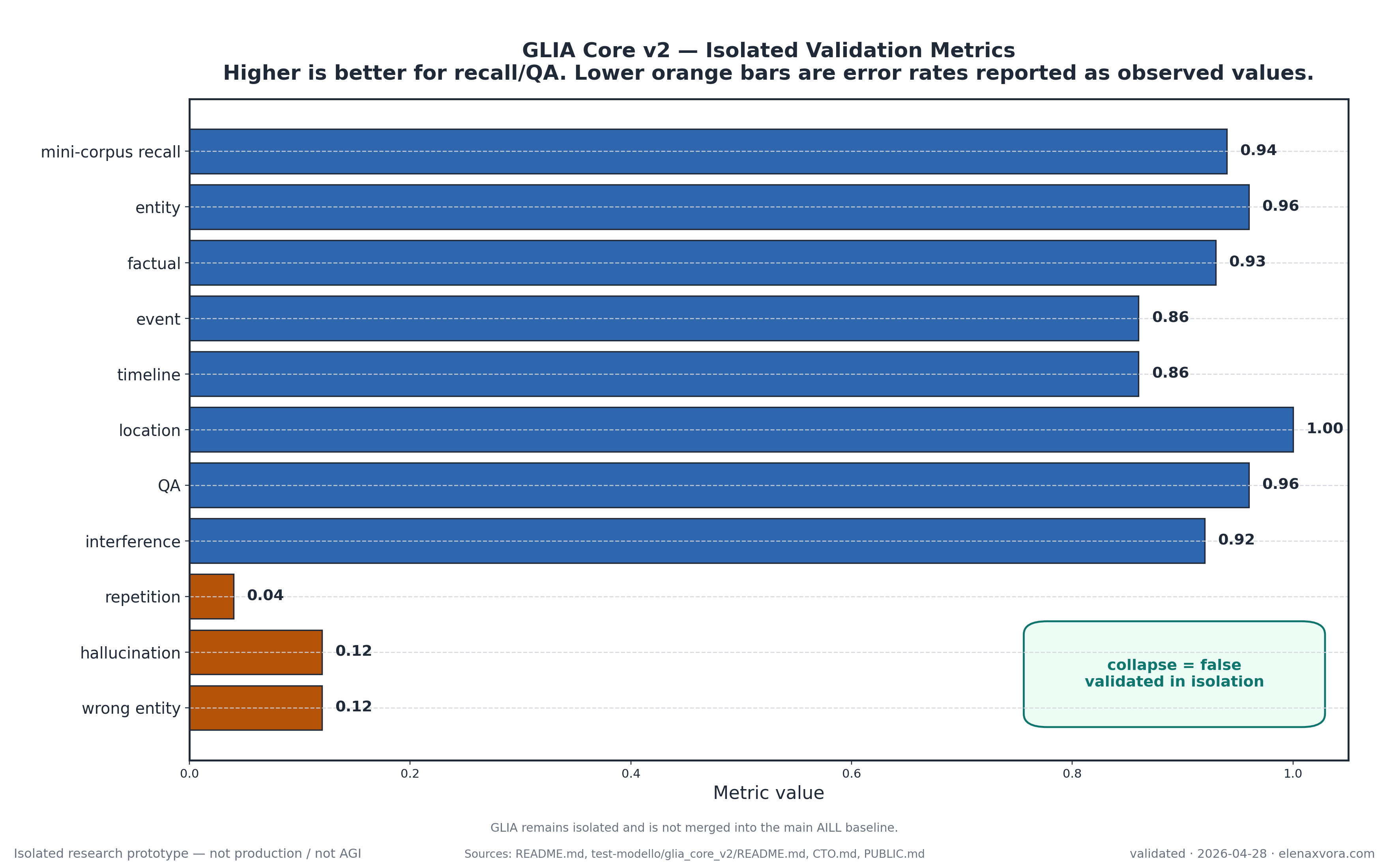
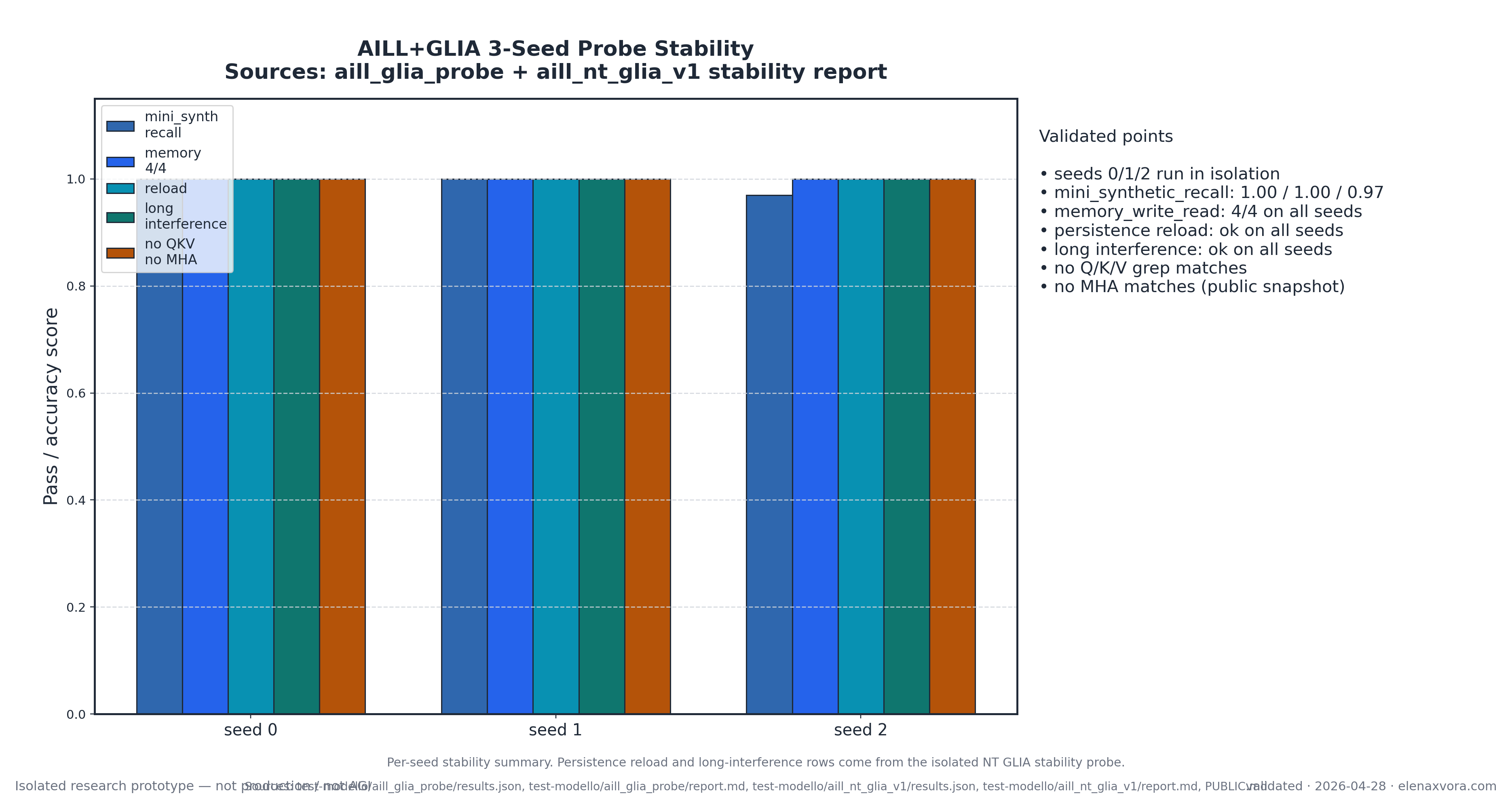
The key distinction is preserved on purpose: GLIA is searchable public research history, not the current serving claim. Keeping that difference explicit makes the site more indexable and less misleading because historical validation and current runtime status are not merged into one vague headline.
SenzaAdam Big Brain
The persistent memory and context layer. Replaces the classical optimizer with a native accumulation rule that retains knowledge across sessions without resetting weights between contexts.
Unlike a standard neural network trained with Adam or SGD, Big Brain does not compute a global loss. Memory consolidation runs on a fixed cadence — earlier knowledge is not evicted when new knowledge is added.
| Property | Value |
|---|---|
| Learning rule | Local accumulation only |
| Global loss | None — by design |
| Memory retention | Persistent across restarts |
| Scale validated | 100 MB (Phase 42, May 2026) |
| External deps | Zero |
Memory
Persistent verified memory
The validated public path centers on memory that can be ingested, retained, recalled internally, and audited instead of hidden behind opaque generation-only behavior.
Compute
Active path stays bounded
Stage 6 shows cortex_used_ratio 0.878049 with context_used_ratio 0.0, reinforcing that the active memory path is actually used during the validated benchmark flow.
Scope
Benchmark evidence, not product marketing
The public framing stays on verified memory behavior, source traceability, and modular runtime validation.
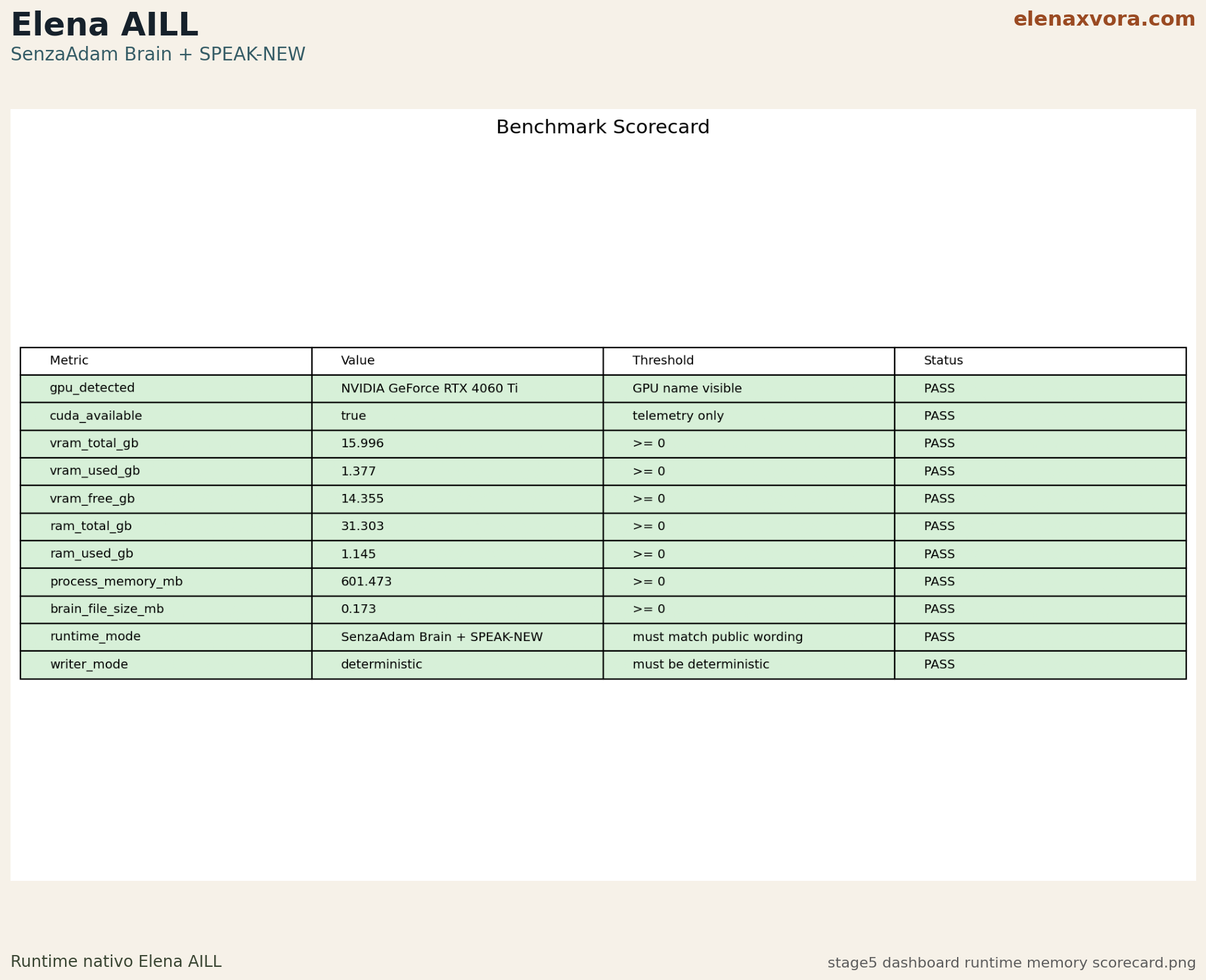
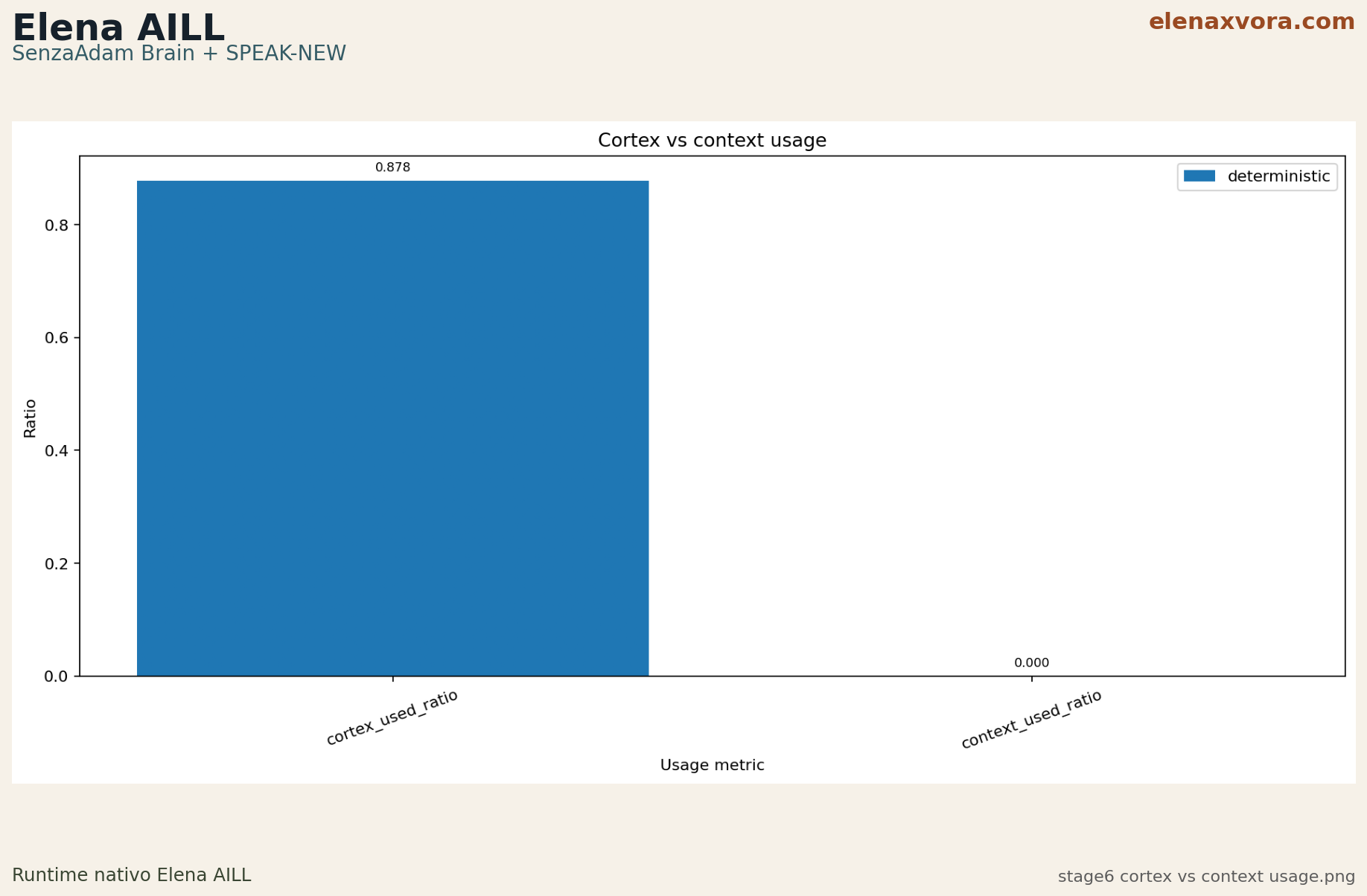
This is why the SenzaAdam section talks in terms of anti-forgetting, active cells, cortex usage, and persistent brain size. Those are concrete signals that help both human readers and search systems understand what kind of memory behavior the project is actually validating.
Clean Speak / SPEAK-NEW Lineage
Clean Speak is the current layer used to turn internal Big Brain context into controlled Italian written answers. SPEAK-NEW remains documented as the earlier validated memory-to-language lineage, so older benchmark language stays searchable without confusing the current runtime formula.
The project is careful here because better phrasing alone is not enough; the public release threshold depends on language quality staying grounded in internal memory context, traceability, and controlled response behavior.
Writer mode
Deterministic is the default
The public benchmark pack keeps the deterministic writer as the default validated mode while the decoder remains optional and experimental.
Language
Controlled Italian answers
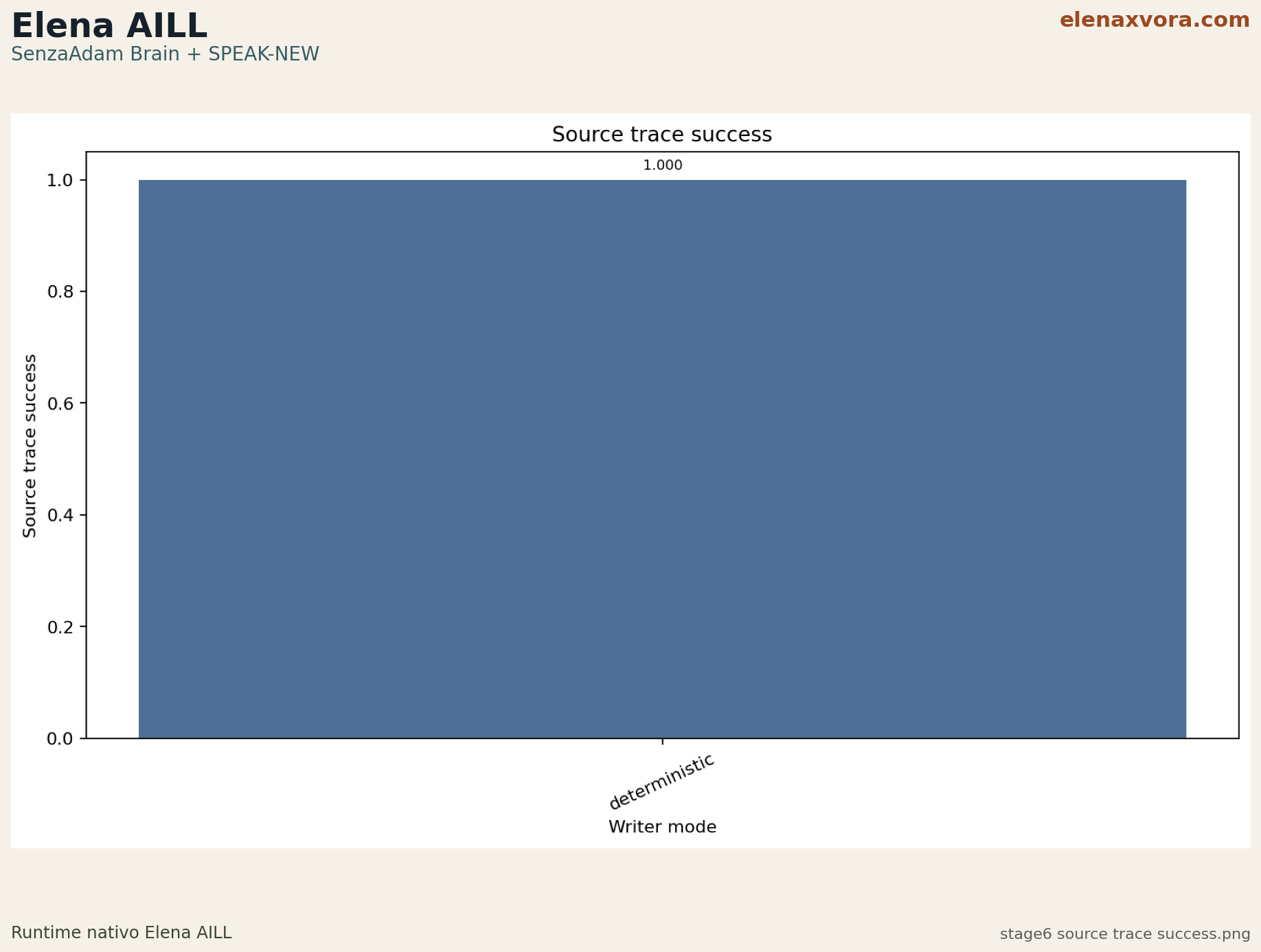
Stage 6 reaches answer_valid_italian_ratio 1.0 while preserving source_trace_success 1.0 on the self-documentation evaluation set.
Release gate
Output quality comes before broader claims
The current priority is better output quality while remaining memory-grounded, not widening claims beyond what the runtime has already validated.
That is also why controlled written output remains the default public reference point. It gives the cleanest benchmark surface for evaluating memory-grounded language behavior while broader generation remains secondary until it can be documented with the same level of reliability.
Native Hebbian Cells
Connection units that strengthen when both the source and target cells are active simultaneously. This is the only weight update mechanism in the system — there is no gradient signal of any kind.
Every cell in the system uses this rule. There is no layer that falls back to standard gradient descent as a fallback. The constraint is architectural, not a configuration option.
SenzaAdam optimizer
A custom optimizer that does not use gradient moments (no first or second moment estimates as in Adam). Finalized and stabilized in Phase 41. The optimizer is not a wrapper around PyTorch's optimizer base class — it is implemented independently.
Runtime environment
| Property | Value |
|---|---|
| Compute | CUDA-accelerated · WSL/Linux |
| External LLM calls | Zero — at any runtime stage |
| Borrowed weights | None |
| Identity stability | Verified Phase 16b · Stable since |
| Backpropagation | Removed Phase 41 · Not present anywhere in pipeline |
Training phases
All phases
Chronological record of every training phase. Each phase builds directly on the previous. There have been no regressions, no architecture pivots, and no rebrands across the full history of the project.
◆
This page now lists both the early core phases and the later public-safe publication phases already documented in the repository. Internal-only work may still exist between published checkpoints, but the publicly described phase record is expanded here instead of being compressed into only a few macro blocks.
Phase groups
Phase 1–10
Architecture foundations
Done
March 2026
Core cell-to-cell connection logic established. Native Hebbian rule prototyped. No global loss function from the very first implementation. Architecture decisions made in this block form the immutable base of all later work.
Phase 11–20
Critic sidecar · No-attention path
Done
April 2026
First clean no-attention path. Critic module implemented and validated in isolation (Phase 11c). No-attention chooser calibration completed (Phase 12f). Shadow dry-run confirmed no regression on earlier checkpoints.
Phase 21–30
Unified runtime · Clean Speak
Done
May 2026
Unified critic and runtime (Phase 22). Output repair work (Phase 28). Natural output repair stabilized (Phase 30b). Clean Speak became the stable output module. 1 million parameter milestone validated during this block.
Phase 31–40
Speak from zero · Bootstrap repair
Done
May 2026
Speak-from-zero bootstrap (Phase 37c–37f). Bootstrap repair cycles completed. Language speak path v1 functional and validated. Quote and writing repair (Phase 40) finalized. All output paths stable.
Phase 41
No global backpropagation
Done
May 31, 2026
Global backpropagation completely removed from all training paths. SenzaAdam optimizer cleaned and finalized. All weight updates are now computed exclusively from local cell activity. Verified stable across all existing checkpoints with no regression.
Phase 42
Big Brain 100MB — zero backprop
Done
May 31, 2026
Big Brain running stably at 100 MB scale with zero global backpropagation confirmed. Memory accumulation verified. Consolidation cadence validated. No instability observed at this scale. No regressions on earlier checkpoints.
Phase 44
Dialog cells — Micro Brain v5
Done
June 2, 2026
Dialog micro-brain v5 validated end-to-end. Cell-chat native runtime confirmed. All dialog cell interactions are local. No external routing or sampling. Identity outputs stable throughout all test turns.
Phase 45+
Stage 7 — Integration hardening
Active
June 2026
Public website evidence surface refinement. Runtime framing and public artifact alignment. Stage 7 integration hardening. Currently in progress and focused on coherence between claims, artifacts, and validated runtime behavior.
Phase 51+
100M parameter target
Planned
TBD
The next scale milestone. Architecture is ready for scale — only training compute and validation time are required. Demo access is gated behind Stage 7 completing first.
Published later phases
Phase 69
Hebbian / synaptic consolidation hardening
Done
Public-safe published
Phase 69 validated synaptic consolidation for the SenzaAdam Big Brain + Clean Speak path. The memory line stopped being only accumulation and started reinforcing local links while preserving old recall.
README data
- Gate: PASS
- Synapses reinforced: 325
- Weak links softened: 19
- Merge candidates: 279
- Old recall: 9/10
- New recall sample: 100/100
- Anti-forgetting score: 1.0
- Active cells average: 3.0
- Reload from checkpoint: PASS
Phase 70
Modular memory scale-up to 10k facts
Done
Public-safe published
Phase 70 validated the controlled jump from 1k to 10k persistent facts while keeping Big Brain as internal memory only and Clean Speak as the final output layer.
README data
- Gate: PASS
- Facts applied: 10,000
- Semantic fact index count: 11,056
- Old recall: 10/10
- Phase 68 recall: 100/100
- New recall sample: 1000/1000
- Anti-forgetting score: 1.0
- Active cells average: 3.0
- Reload from checkpoint: PASS
Phase 71
Official runtime 10k conversation probe
Done
Public-safe published
Phase 71 validated the official runtime path after the 10k scale-up in a realistic conversation probe, with Big Brain used as context only and Clean Speak as final output layer.
README data
- Status: PASS
- Probe prompts: 100
- Sensible answers: 100/100
- Context used: 100/100
- Ambiguity defer: 15/15
- Old recall: 10/10
- New recall sample: 1000/1000
- Anti-forgetting score: 1.0
- Active cells average: 3.0
Phase 72
Clean SynapticMemory backend V1
Done
Public-safe published
Phase 72 recovered the old SynapticMemory idea as a clean bounded sparse backend without importing the old runtime directly.
README data
- Status: PASS
- Backend created: aill_synaptic_memory_backend_v1
- Pre-integration test: PASS
- Post-integration test: PASS
- Official runtime 10k smoke: PASS
- Sensible: 100/100
- Context used: 100/100
- Ambiguity defer: 15/15
- Active cells average: 3.0
Phase 73
GLIA stability layer V1
Done
Public-safe published
Phase 73 recovered the GLIA stability idea as a clean optional guard for fragile context, conflicting signals, and active-path pressure.
README data
- Status: PASS
- Backend created: aill_glia_stability_layer_v1
- Pre-integration test: PASS
- Post-integration test: PASS
- Official runtime 10k smoke: PASS
- Sensible: 100/100
- Context used: 100/100
- Ambiguity defer: 15/15
- Active cells average: 3.0
Phase 74Runtime learn / confirm loopDonePublic-safe published
Phase 74 validated controlled runtime learning: Elena proposes updates, asks for confirmation, writes only confirmed facts into a working brain, and rejects unconfirmed information.
README data
- Status: PASS
- Proposals: 10
- Confirmed updates written: 8
- Rejected updates not saved: 2
- Reload from checkpoint: PASS
- Confirmed recalled after reload: 8/8
- Rejected absent after reload: 2/2
- Hallucination added: 0
Phase 75Conflict resolutionDonePublic-safe published
Phase 75 validated conflict protection before `.brain` updates: confirmed facts persist, contradictory ones are blocked, and ambiguous ones are routed to clarification.
README data
- Status: PASS
- Status match: 10/10
- Applied updates: 5
- Blocked conflicts: 3
- Clarification items: 1
- Duplicate/protected items: 1
- Applied recalled after reload: 5/5
- Blocked absent after reload: 3/3
Phase 76Long conversation memoryDonePublic-safe published
Phase 76 validated temporary conversation memory with safe consolidation: stable confirmed items persist after reload while volatile details stay outside persistent memory.
README data
- Status: PASS
- Conversation turns: 13
- Stable candidates: 3
- Consolidated candidates: 3
- Reload from checkpoint: PASS
- Consolidated recalled after reload: 3/3
- Volatile facts absent after reload: 3/3
Phase 77Big Brain 100k controlled scaleDonePublic-safe published
Phase 77 validated the controlled 100k memory scale step and proved that the large index remained grounded, bounded, and reloadable.
README data
- Status: PASS
- New facts applied: 100,000
- Semantic fact index after reload: 111,071
- Reload from checkpoint: PASS
- Indexed new-fact recall sample: 100/100
- Runtime micro-smoke: 10/10
- Anti-forgetting score: 1.0
- Active cells average: 3.0
Phase 78Fast 100k runtime recallDonePublic-safe published
Phase 78 turned the 100k checkpoint into a practical runtime recall result with fast internal cache-based retrieval instead of broad scan per prompt.
README data
- Status: PASS
- Runtime recall new prompts: 100/100
- Old memory prompts: 5/5
- Average recall latency: under 50 ms
- P95 recall latency: under 50 ms
- Active cells average: 3.0
- Hallucination added: 0
Phase 79Official 100k conversation runtimeDonePublic-safe published
Phase 79 validated the official 100k conversation runtime on a full prompt probe, with Big Brain used only as internal context.
README data
- Status: PASS
- Sensible responses: 100/100
- Prompts using Big Brain context: 100/100
- Ambiguous prompts deferred: 20/20
- P95 latency: under 50 ms
- Active cells average: 3.0
- Hallucination added: 0
Phase 80100k runtime freeze milestoneDonePublic-safe published
Phase 80 froze the validated 100k runtime as an internal stable milestone while keeping the frozen checkpoint private and auditable.
README data
- Status: PASS
- Frozen milestone created
- Source and frozen hashes match
- Reload from frozen checkpoint: PASS
- Runtime smoke sensible: 10/10
- Ambiguous prompts deferred: 4/4
- P95 latency: under 50 ms
Phase 81Private demo frozen 100kDonePublic-safe published
Phase 81 validated the frozen F80 runtime on a broader private 200-prompt demo probe.
README data
- Status: PASS
- Sensible responses: 200/200
- Prompts using Big Brain context: 200/200
- Ambiguous prompts deferred: 40/40
- P95 latency: under 50 ms
- Active cells average: 3.0
Phase 82Interactive chat CLI frozen 100kDonePublic-safe published
Phase 82 introduced the manual terminal chat path for talking to Elena on the frozen 100k runtime without any checkpoint writes or training.
README data
- Status: PASS
- Interactive CLI created
- Test smoke: 5/5 sensible responses
- Ambiguous prompt defer: 1/1
- Checkpoint touched: false
- Training started: false
Phase 83Clean Speak output expansion plus GPUDonePublic-safe published
Phase 83 fixed a major runtime weakness: strong memory but too few output patterns. The output layer became broader and GPU-backed.
README data
- Status: PASS
- Speech validation prompts passed: 100/100
- Template repetition rate: below 0.15
- False defer count: 0
- Conversation: 30/30
- Identity/capability: 20/20
- Python/code/debug: 20/20
- Ambiguity defer: 20/20
Phase 84Learned speech composer V1DonePublic-safe published
Phase 84 moved Clean Speak away from rigid runtime templates toward a learned text state built from sentence transitions and family-specific word structure.
README data
- Status: PASS
- Learned speech composer active
- Template runtime disabled in test
- Validation prompts passed: 60/60
- Repetition rate: below 0.20
- GPU path active
- Checkpoint touched: false
Phase 85Learned speech composer V1 extendedDonePublic-safe published
Phase 85 extended the learned output state and hardened the runtime smoke test with lower repetition while keeping Big Brain as memory/context only.
README data
- Status: PASS
- Sensible responses: 100/100
- Fixed runtime templates used: false
- Repetition rate: 0.060000
- GPU path: active
- Checkpoint writes: none
Phase 86Memory-conditioned speechDonePublic-safe published
Phase 86 let internal Big Brain context influence the speech composer without allowing memory to generate the final answer directly.
README data
- Status: PASS
- Sensible responses: 120/120
- Memory-conditioned responses: 88
- Fixed runtime templates used: false
- Repetition rate: 0.066667
- GPU path: active
Phase 87Speech routing hardeningDonePublic-safe published
Phase 87 hardened the output router so ordinary prompts, simple math, capability questions, and typo-heavy requests were no longer hijacked by unrelated memory context.
README data
- Status: PASS
- Bug cases passed: 14/14
- False memory conditioning: 0
- GPU path: active
- Fixed runtime templates used: false
- Checkpoint writes: none
Phase 88Unlabeled speech trainingDonePublic-safe published
Phase 88 trained the output state from unlabeled natural text instead of prompt-answer pairs while keeping the runtime clean.
README data
- Status: PASS
- Sensible responses: 200/200
- False memory conditioning: 0
- Repetition rate: 0.060000
- GPU path: active
- Supervised prompt-response training: false
Phase 895GB speech training gateNot promotedPublic-safe published
Phase 89 staged a clean 5GB dataset gate and trained a broader speech state, but manual smoke exposed corpus-style phrasing so the result stayed experimental and was not promoted.
README data
- Status: CREATED / NOT PROMOTED
- Selected size: 5.268907 GB
- Automated runtime check: PASS
- Manual smoke: FAIL_NOT_PROMOTED
- Default runtime restored to F88
- GPU path: active
Phase 9110GB speech and practical gateDonePublished summary
Phase 91 promoted the 10GB speech and practical gate after manual smoke. The public repo currently exposes the milestone summary, but not a dedicated per-phase README under `da-pubblicare`.
Phase 92Chat regression hardeningDonePublished summary
Phase 92 hardened chat regression around identity, capability, memory, and uncertainty responses. The public repo currently exposes the milestone summary, but not a dedicated per-phase README under `da-pubblicare`.
Phase 9320GB speech and practical gateDonePublished summary
Phase 93 passed the 20GB speech and practical gate with GPU-batched scoring on RTX 4060 Ti. The public repo currently exposes the milestone summary, but not a dedicated per-phase README under `da-pubblicare`.
Phase 94Practical output depth gateDonePublished summary
Phase 94 passed the practical output depth gate for code, debug, work messages, and document summaries. The public repo currently exposes the milestone summary, but not a dedicated per-phase README under `da-pubblicare`.
Phase 95Elena vs LLM-style baseline benchmarkDonePublic-safe published
Phase 95 added the first local repeatable Elena vs LLM-style baseline benchmark and finally exposes the exact benchmark deltas instead of a vague comparison sentence.
README data
- Status: PASS
- Cases: 20
- Elena overall: 4.05/5
- Baseline overall: 1.275/5
- Elena wins: 19
- Baseline wins: 0
- Ties: 1
- Code: Elena 5.0/5 vs Baseline 1.0/5
- Debug: Elena 4.0/5 vs Baseline 2.0/5
- Math: Elena 4.0/5 vs Baseline 4.0/5
- Memory: Elena 4.0/5 vs Baseline 1.0/5
- Safety: Elena 4.0/5 vs Baseline 1.0/5
Phase 96
Continual learning work checkpoint
Done
Public-safe published
Elena received a small verified local memory update, saved it into a work brain checkpoint, reloaded from zero, and preserved both prior and new memory. This is the public-safe continual-learning milestone before runtime promotion.
Phase 97
Runtime promotion gate for F96
Done
Public-safe published
The F96 work checkpoint was tested inside the live runtime path before promotion. Clean Speak remained the final output layer, no training ran, and no checkpoint overwrite was performed during the gate.
Phase 98
Frozen F80 vs work F96 runtime A/B
Done
Public-safe published
The frozen F80 runtime and the F96 continual-learning work checkpoint were compared on the same local runtime prompts. No training, repair, checkpoint write, or frozen overwrite was performed during the comparison.
Phase 99
F96 promoted to new frozen runtime
Done
Public-safe published
The validated F96 work checkpoint was promoted into a new frozen runtime milestone while preserving the older F80 frozen checkpoint. This phase marks the runtime promotion boundary, not a retraining phase.
Phase 100Enterprise manual runtime gateDonePublic-safe published
Phase 100 ran the 100-prompt enterprise-style manual gate on the promoted F99 runtime without training, repair, or checkpoint writes.
README data
- Status: PASS
- Readable pass: 95/100
- Sensible pass: 90/100
- Ambiguity pass: 16/16
- Latency avg ms: 87.406
- Capability: 5/5
- Code: 5/5
- Document: 10/10
- Memory: 14/15
Phase 101F99 runtime hardeningDonePublic-safe published
Phase 101 hardened the enterprise/work composer and ambiguity handling of F99 without any training or checkpoint writes.
README data
- Status: PASS
- Sensible before: 75/100
- Sensible after: 81/100
- Ambiguity before: 12/16
- Ambiguity after: 13/16
- Pseudo-word ratio: 0.005263
Phase 102Memory priority and ambiguity hardeningDonePublic-safe published
Phase 102 improved grounded memory routing and made ambiguity/defer behavior stricter without training or checkpoint writes.
README data
- Status: PASS
- Sensible before: 81/100
- Sensible after: 85/100
- Ambiguity before: 13/16
- Ambiguity after: 16/16
- Latency avg ms: 79.027
Phase 103Enterprise gate 90/100DonePublic-safe published
Phase 103 raised the promoted F99 runtime to a 90/100 sensible enterprise gate without training or checkpoint writes.
README data
- Status: PASS
- Sensible before: 85/100
- Sensible after: 90/100
- Ambiguity before: 16/16
- Ambiguity after: 16/16
- Latency avg ms: 87.406
Phase 104Blind runtime validationFailPublic-safe published
Phase 104 deliberately exposed the promoted F99 runtime to a new blind prompt set and showed that the previous enterprise gate did not generalize well enough.
README data
- Status: FAIL
- Readable pass: 99/100
- Sensible pass: 59/100
- Ambiguity pass: 13/15
- Latency avg ms: 82.525
- Capability: 1/4
- Conversation: 1/4
- Debug: 1/4
- Math: 4/4
Phase 105Blind failure learning diagnosticDonePublic-safe published
Phase 105 turned F104 blind failure families into local brain updates instead of prompt-answer patching, while leaving the promoted frozen F99 checkpoint untouched.
README data
- Status: PASS
- Families updated: 9
- Cells updated: 54
- Synapses updated: 135
- Weights updated: 894
- Semantic fact index count: 111090
- Checkpoint created: true
- Frozen checkpoint overwritten: false
Phase 106Learned signal gating diagnosticFailPublic-safe published
Phase 106 hardened the runtime gate for the learned signal family created in F105, but the retest still failed the target quality bar.
README data
- Status: FAIL
- F104 sensible retest: 65/99
- Holdout sensible: 21/30
- Ambiguity pass: 16/18
- Learned signal seen: 109
- Learned signal used: 0
- Memory: 5/10
- Memory new: 5/10
Phase 107Memory-to-speech calibrationFailPublic-safe published
Phase 107 calibrated how learned memory signals influence speech. It improved some areas but still did not meet the publication bar for the full retest.
README data
- Status: FAIL
- F104 sensible retest: 70/99
- Holdout sensible: 21/30
- Ambiguity pass: 14/18
- Learned signal seen: 109
- Learned signal used: 55
- Explain: 8/8
- Memory new: 3/10
Phase 108–111Hierarchical memory routing and runtime integrationDonePublished summary
This block introduced hierarchical memory routing into the runtime so Elena can use condensed internal context before expanding into larger memory paths. The goal was to keep active context bounded while making the runtime more practical on longer tasks.
README summary
- Hierarchical memory routing: PASS
- Runtime integration: PASS
- Bounded active context preserved
- F99 remains the preserved frozen milestone
Phase 108Hierarchical memory routing V1DonePublished summary
Phase 108 started the hierarchical memory-routing line, introducing a condensed internal routing step before broader memory expansion.
Phase 109Hierarchical routing hardeningDonePublished summary
Phase 109 hardened the first hierarchical routing pass so context selection remained local, bounded, and compatible with the existing runtime path.
Phase 110Bounded context expansionDonePublished summary
Phase 110 refined how the runtime expands from compact context into larger internal memory paths without losing bounded active-context discipline.
Phase 111Hierarchical runtime integrationDonePublished summary
Phase 111 completed the first runtime integration of hierarchical memory routing, making the routing line part of the practical Elena runtime.
Phase 112–114GPU context execution and chat CLI integrationDonePublished summary
This block validated GPU context execution on the RTX 4060 Ti path. Cached GPU context was made substantially faster, and the GPU context path was wired into the manual chat CLI as an optional runtime flag.
README summary
- GPU context path: PASS
- Hardware: RTX 4060 Ti
- F113 cached GPU context: about 9.6x faster than first GPU pass
- F114 chat CLI GPU flag: integrated
Phase 112GPU context executionDonePublished summary
Phase 112 validated GPU context execution on the practical Elena runtime path.
Phase 113Cached GPU context latencyDonePublished summary
Phase 113 reduced cached GPU-context latency by about 9.6x relative to the first GPU pass, making the path more practical in repeated runtime use.
Phase 114Chat CLI GPU context flagDonePublished summary
Phase 114 wired the GPU context path into the manual chat CLI as an optional runtime flag without changing the frozen runtime milestone.
Phase 115–123Real chat quality, hard talk, and readiness validationDonePublished summary
This block improved real chat quality, context alignment, manual talk behavior, local baseline benchmarking, and hard-talk readiness around the preserved F99 line. It is a runtime-hardening series, not a new frozen release.
README summary
- F115 real chat quality audit: PASS
- F118 manual talk regression: 56/60 sensible
- F119 Elena vs local LLM-style baseline: Elena 158/200, baseline 23/200
- F122 hard talk: 480/500 sensible, ambiguity 50/50
- F123 aggregate readiness: 688/760 sensible
- F123 readable: 760/760
- F123 ambiguity defer: 83/91
- F123 pseudo_word_ratio: 0.000000
- GPU context: active
- checkpoint_touched: false
- frozen overwritten: false
Phase 115Real chat quality auditDonePublished summary
Phase 115 audited real chat quality on the live runtime path and marked the starting point of the later readiness block.
README summary
- Status: PASS
Phase 117Context-to-output alignment hardeningDonePublished summary
Phase 117 hardened the alignment between internal context and final runtime output so practical answers stayed grounded without checkpoint writes.
Phase 118Manual talk regression after hardeningDonePublished summary
Phase 118 measured manual talk quality after the later routing and alignment hardening passes.
README summary
- Sensible responses: 56/60
- No checkpoint writes during validation
Phase 119Elena vs local LLM-style baselineDonePublished summary
Phase 119 compared Elena against a local LLM-style baseline, not a live commercial model, to measure practical runtime quality on the same benchmark slice.
README summary
- Elena sensible: 158/200
- Baseline sensible: 23/200
- Live commercial model used: false
- checkpoint_touched: false
Phase 120Hard talk benchmark startDonePublished summary
Phase 120 opened the final hard-talk readiness block around the preserved frozen runtime line.
Phase 121Context routing hardeningDonePublished summary
Phase 121 hardened context routing for practical requests so runtime behavior stayed usable under heavier conversational pressure.
Phase 122Hard talk 500DonePublished summary
Phase 122 ran the 500-prompt hard-talk benchmark as the main practical stress test of the later runtime-hardening line.
README summary
- Sensible responses: 480/500
- Ambiguity defer: 50/50
Phase 123Speaking runtime readinessDonePublic-safe published
Phase 123 aggregated the readiness evidence across F115, F118, and F122 without promoting a new frozen runtime checkpoint. F99 remained the preserved frozen milestone during this validation block.
README data
- Sensible: 688/760
- Readable: 760/760
- Ambiguity defer: 83/91
- pseudo_word_ratio: 0.000000
- GPU context: active
- checkpoint_touched: false
- training_started during validation: false
- frozen_checkpoint_overwritten: false
Phase 135–156Research-state runtime expansion, skills, cleanup, and dataset preparationDonePublished summary
This later block added larger research-state speech runs, planner routing, optional CodeSkill and Message/Document skills, controlled cleanup of legacy external material, routing fixes, and a cleaned dataset for future controlled training.
Phase 13550GB GPU speech-state research runDonePublished summary
Phase 135 completed a larger 50GB GPU speech-state run on the RTX 4060 Ti path as a research state, but it was not promoted as the official frozen runtime.
README summary
- Status: PASS / research state not promoted
- Scanned data: 50.0 GB
- Accepted sentences: about 1.8M
- Neutral Elena-only validation: 50/50
- Frozen checkpoint overwritten: false
Phase 139-BResponse Planner V1DonePublished summary
Phase 139-B added Response Planner V1 as a routing layer, not as a prompt-answer lookup and not as a new brain checkpoint. The 50GB state remained research-only because it did not beat the default state after planner hardening.
README summary
- Chat regression: PASS
- 50GB A/B chat: 58/60
- Neutral Elena-only: 50/50
- Runtime audits: PASS
- checkpoint_writes: none
Phase 141CodeSkill V1 recoveryDonePublished summary
Phase 141 recovered CodeSkill V1 as a clean optional module inside `aill_originale`, keeping code and debug structure separate from old external scripts.
README summary
- Smoke checks: PASS
- Runtime audits: PASS
- checkpoint_writes: none
- JSON runtime memory: not used
Phase 142CodeSkill V1 runtime integrationDonePublished summary
Phase 142 integrated CodeSkill V1 as an optional runtime path for code and debug prompts.
README summary
- CodeSkill benchmark: 20/20
- Chat regression: PASS
- Runtime audits: PASS
- Checkpoint or frozen runtime modified: false
Phase 143Message and Document Skill V1DonePublished summary
Phase 143 integrated Message/Document Skill V1 as an optional runtime path for practical messages and document prompts.
README summary
- Message/Document benchmark: 15/15
- CodeSkill benchmark: 20/20
- Chat regression: PASS
- Runtime audits: PASS
- External target-answer data imported: false
Phase 144External speak dataset archiveDonePublished summary
Phase 144 archived old external speak datasets and rollback backups with target-answer or retrieval-style fields out of the active clean project path.
README summary
- Active clean project: `test-modello/aill_originale`
- Chat regression: PASS
- CodeSkill: PASS
- Message/Document Skill: PASS
- Runtime audits: PASS
Phase 145Prepared dataset archiveDonePublished summary
Phase 145 archived old external prepared dataset versions out of the repository root while keeping them preserved for traceability.
README summary
- Active clean project: `test-modello/aill_originale`
- Post-cleanup runtime checks: PASS
Phase 146Legacy app and tool archiveDonePublished summary
Phase 146 archived old external app, demo, autolearning, training, and tool folders out of the active root while preserving them for traceability.
README summary
- Active clean runtime path: `test-modello/aill_originale`
- Post-cleanup runtime checks: PASS
Phase 147Remaining external root auditDonePublished summary
Phase 147 audited the remaining external root folders including old root code, scripts, checkpoints, benchmark packs, generated outputs, rescue checkpoints, and the large corpus vault.
README summary
- Files moved in this audit: none
- Active clean project: `test-modello/aill_originale`
Phase 153Clean Speak routing fixDonePublished summary
Phase 153 fixed Clean Speak routing around real chat failures. Big Brain remained context-only, practical routing improved, and checkpoints stayed untouched.
Phase 155Generative Speech Core V1DonePublished summary
Phase 155 added Generative Speech Core V1 as a controlled speaking component to improve sentence composition without letting Big Brain generate final answers.
README summary
- Chat regression: PASS
- CodeSkill: PASS
- Message/Document Skill: PASS
- Runtime audits: PASS
Phase 15610GB cleaned speech dataset preparationDonePublished summary
Phase 156 prepared a 10GB cleaned speech dataset from available corpus material for future controlled training without creating or promoting a new checkpoint in this phase.
README summary
- Dataset preparation: completed
- Promoted checkpoint created: false
- Public runtime release changed: false
Phase 148Remaining external root archiveDonePublished in root README
Phase 148 completed the controlled cleanup of the remaining external root folders and made `test-modello/aill_originale` the only active runtime and development path.
README data
- Status: PASS
- Archived files: 2,930
- Archived bytes: 5,550,970,124
- Dataset libri touched: false
- Checkpoint touched: false
- Chat regression: PASS, 29/30 sensible
- Message/Document skill: PASS, 15/15
- CodeSkill: PASS, 20/20
Phase 149Speech runtime follow-up hardeningDonePublished in root README
Phase 149 targeted short follow-up prompts such as `si fallo`, `ok procedi`, and `continua`, reducing generic fallback behavior without changing the default speech state.
README data
- Status: PASS
- GPU used: true, RTX 4060 Ti
- F149 test: 31/32 sensible
- Pseudo-word ratio: 0.000000
- Chat regression: PASS, 29/30 sensible
- Message/Document skill: PASS, 15/15
- CodeSkill: PASS, 20/20
- Speech state promoted: false
Phase 150Conversation carryover runtimeDonePublished in root README
Phase 150 added a small runtime carry-over layer for short multi-turn chat so Elena can use the previous task context on concise follow-up turns.
README data
- Status: PASS
- Conversation carry-over test: 14/14 sensible
- Carry-over used: 6 turns
- Pseudo-word ratio: 0.000000
- Chat regression: PASS, 29/30 sensible
- Message/Document skill: PASS, 15/15
- CodeSkill: PASS, 20/20
- Persistent learning: not changed
Phase 151Elena Action Composer V1DonePublished in root README
Phase 151 introduced the first Action Composer layer between memory/context and final speech for executable tasks such as code, messages, and technical explanations.
README data
- Status: PASS
- Action Composer benchmark: 16/16 sensible
- Action composer used: 6
- Pseudo-word ratio: 0.000000
- F150 carry-over regression: PASS, 14/14
- Chat regression: PASS, 28/30 sensible
- Message/Document skill: PASS, 15/15
Timeline
Milestone log
Key validated checkpoints in the Elena AILL research program. Every milestone listed here is backed by a reproducible benchmark run. No results are estimated or extrapolated.
Monthly Research Updates
Elena AILL is updated as an active research project. Each monthly update summarizes validated benchmark milestones, training status, integration progress, and next public validation steps.
New monthly sections are added only when the underlying result is validated and traceable. The timeline stays chronological month by month: historical milestones remain visible, the current month gets its own update card, and future work is described only after the last validated month already shown in public.
This slower cadence is deliberate. AILL Research updates function more like an engineering notebook and less like a product launch feed, so missing evidence stays private until it becomes measurable, reviewable, and fit for publication.
April 2026
1M SenzaAdam Milestone
Status: Completed historical milestone
Key updates
- Elena AILL main project preserved
- GLIA isolated validation completed
- SenzaAdam 1M real-data brain passed
- 1,000,000 real concept and fact pairs
- 1,083,323 learned_facts
- 104,078 created_cells
- 979,245 reused_cells
- recall_score = 0.9767
- anti_forgetting_score = 1.0000
- active_cells_avg = 1.00
- no Adam
- no global backward
May 2026
10M SenzaAdam Milestone
- verified_10m_result = PASS
- sample_facts = 10,000,000
- learned_facts = 10,833,323
- created_cells = 394,856
- reused_cells = 10,438,467
- recall_score = 0.9883
- anti_forgetting_score = 1.0
- active_cells_avg = 1.0
- brain_file_size_mb = 2358.25
June 2026
Website package and integration alignment
- public website narrative aligned around Elena AILL main project
- current public runtime wording centered on SenzaAdam Big Brain + Clean Speak
- verified 10M result kept as the public reference milestone
- 100M stress run deferred, not failed
- SenzaAdam Big Brain + Clean Speak integration hardening continues
- SPEAK-NEW remains documented as historical lineage
- public benchmark package refresh stays limited to real PNG artifacts only
- Stage 7 remains focused on integration, packaging, and public surface coherence
- public claims remain limited to validated evidence and shipped artifacts
Apr 2026
Validated
Validated
1M parameters — first scale validation
Historical milestone. Strong retention results and bounded active cells confirmed that the architecture scales correctly from the very first checkpoint. No instability observed during the validation run. This result established the first public-facing evidence point for the project.
May 2026
Validated
Validated
10M parameters — reference benchmark milestone
The reference benchmark result for the public narrative. Big Brain and Clean Speak integrated as the stable official architecture for all subsequent work. All benchmark conditions passed including long context window tests. Activation remained bounded throughout. This is the milestone cited in all public-facing documentation.
May 31
Validated
Validated
Zero backpropagation — architecture complete
Phase 41 removed global backpropagation from the entire training pipeline. The architecture is now fully local — no gradient signal is computed at any stage. This was the final architectural constraint required before the system could be described as genuinely native.
Jun 2026
Active
Active
Stage 7 — integration hardening
Currently in progress. Public evidence surface refinement, runtime framing, and Stage 7 integration hardening. The goal is a cleaner public package with tighter alignment between documentation, artifacts, and validated runtime behavior. Estimated completion within June 2026.
TBD
Planned
Planned
100M parameters — next scale target
Architecture is confirmed ready for this scale. Training compute allocation and validation schedule will be finalized after Stage 7 completes. This milestone is not gated on any architectural change — only on training time and compute availability.
Benchmarks
Results — 10M suite
The 10M parameter benchmark suite was run in May 2026. All checks below are reproducible. No results are cherry-picked, extrapolated, or measured under non-representative conditions.
Verified 10M internal benchmark result
The 10 million data milestone completed: internal 10M SenzaAdam benchmark evidence in the repo marks verified_10m_result as PASS on the read-only benchmark report.
The importance of this milestone is not scale alone. The stronger claim is that the benchmark remains stable while scale increases: retention stays high, anti-forgetting stays at the validated threshold, and the active path remains tightly bounded instead of expanding into broad opaque compute.
That is why the public wording stays narrow. The site reports a verified persistent-memory result under a specific benchmark protocol, not a general intelligence claim and not a promise that every private runtime component is already public.
learned_facts10,833,323
created_cells394,856
reused_cells10,438,467
recall_score0.9883
Retention
anti_forgetting_score = 1.0
The read-only 10M report shows no retention degradation in the validated benchmark threshold set.
Active path
active_cells_avg = 1.0
The active memory path remains tightly bounded instead of scaling by activating broad global compute.
Brain artifact
brain_file_size_mb = 2358.2526
The verified 10M benchmark report records a single persistent brain artifact instead of optimizer-state-heavy checkpoints.
Training constraints
No Adam, no global backward
The active memory path remains local-update based, with no Adam optimizer state and no global backward pass.
Taken together, these values show why the 10M result became the reference milestone for the current public narrative. More facts were learned, more cells were created and reused, retention stayed measurable, and the brain artifact remained explicit enough to describe as a persistent object rather than as a hidden optimizer-heavy side effect.
The roadmap shifted after strong 10M evidence, so 100M was deferred rather than failed
The 100M stress run was deferred, not failed, because the 10M run had already produced sufficiently strong evidence to shift engineering focus toward integration, public benchmark packaging, SenzaAdam Big Brain + Clean Speak validation, and Stage 7 runtime hardening for stronger written output, coding reliability, and document quality.
Deferral here is a prioritization choice, not a hidden negative result. Once the 10M run supplied a defensible benchmark story, the more valuable engineering problem became how to connect memory, language, runtime controls, and public evidence without creating a misleading public product surface.
System integration
Engineering effort moved away from a larger stress run toward cleaner runtime integration and architecture clarity.
Public benchmark packaging
The website and public package now prioritize traceable reports, metrics summaries, and real PNG artifacts only.
Big Brain + Clean Speak
Stage 2 through Stage 6 validation remains historical proof surface, while the current Elena AILL formula is SenzaAdam Big Brain + Clean Speak.
Stage 7 runtime hardening
The next public step is not bigger scale alone. It is better written output quality and cleaner runtime integration while staying grounded in memory.
This is also why the website is organized around benchmark explanation rather than just milestone celebration. A larger raw number would not have improved the public understanding of Elena AILL as much as a cleaner explanation of what the current validated Applied AI stack already proves.
Validated runtime, writer, and self-documentation benchmark evidence
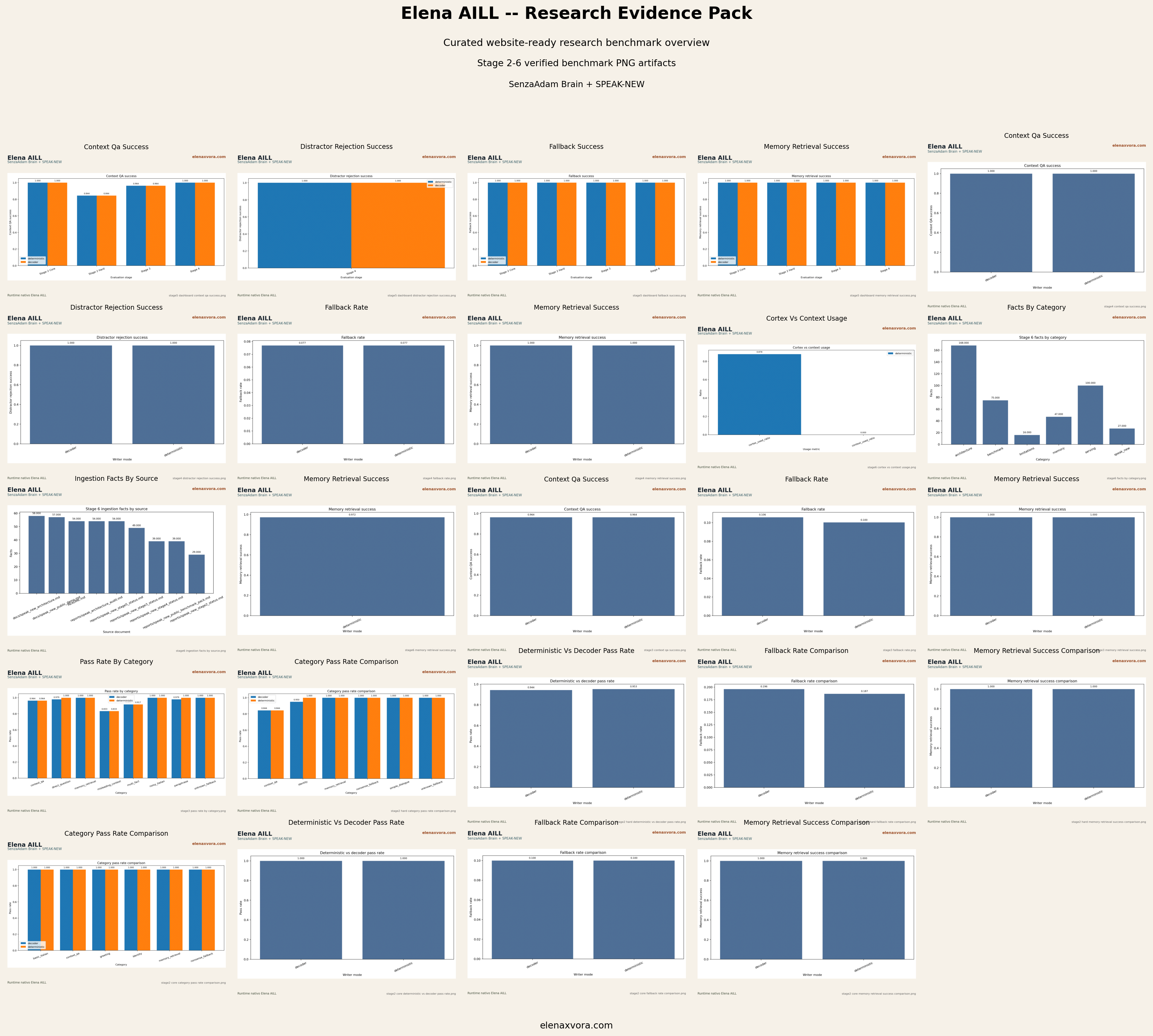
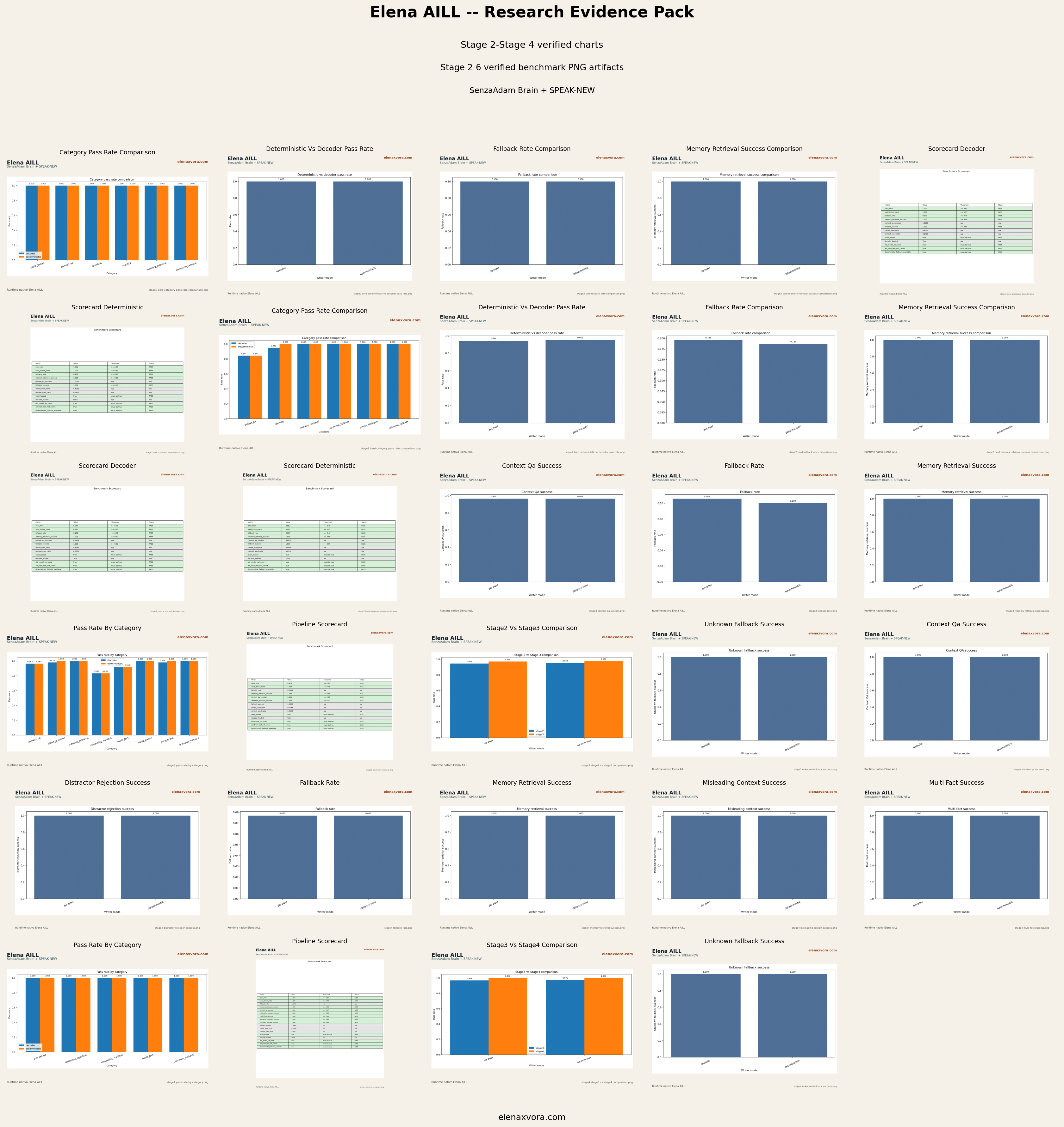
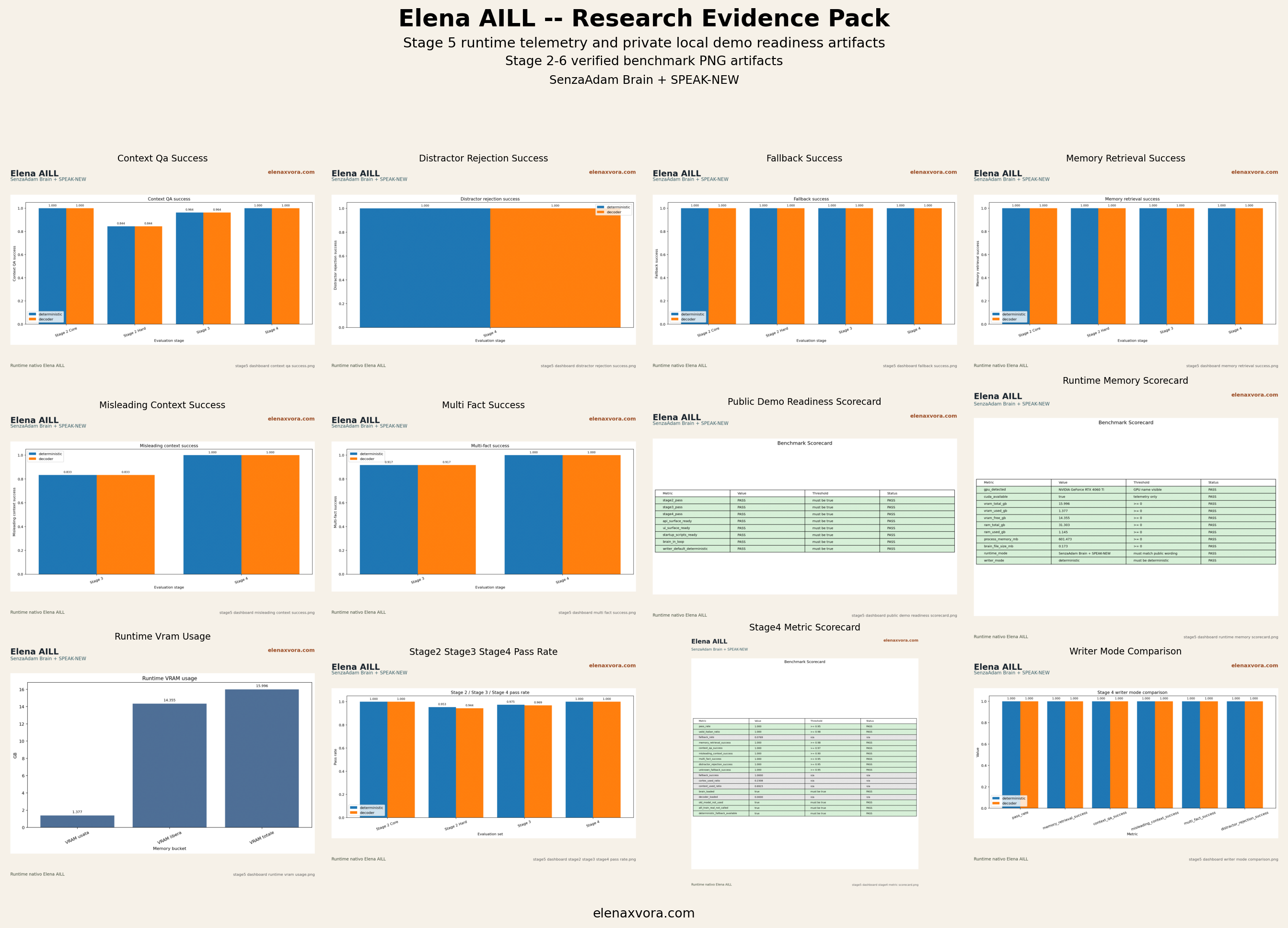
The figures below are real PNG artifacts copied from the public benchmark pack and supporting reports only. No fake charts, no invented metrics, and no AI-generated infographic evidence are used here.
Each stage answers a different benchmark question. Stage 2 establishes core behavior, Stage 3 and Stage 4 increase robustness pressure, Stage 5 validates runtime behavior, and Stage 6 validates self-documentation, source traceability, and memory-grounded answering.
From an Applied AI perspective, this progression matters because it shows more than raw score accumulation. It shows whether a memory-grounded system can keep internal-recall discipline, fallback behavior, runtime accountability, and explainable sourcing while the public claims remain conservative.
Stage 2
PASS
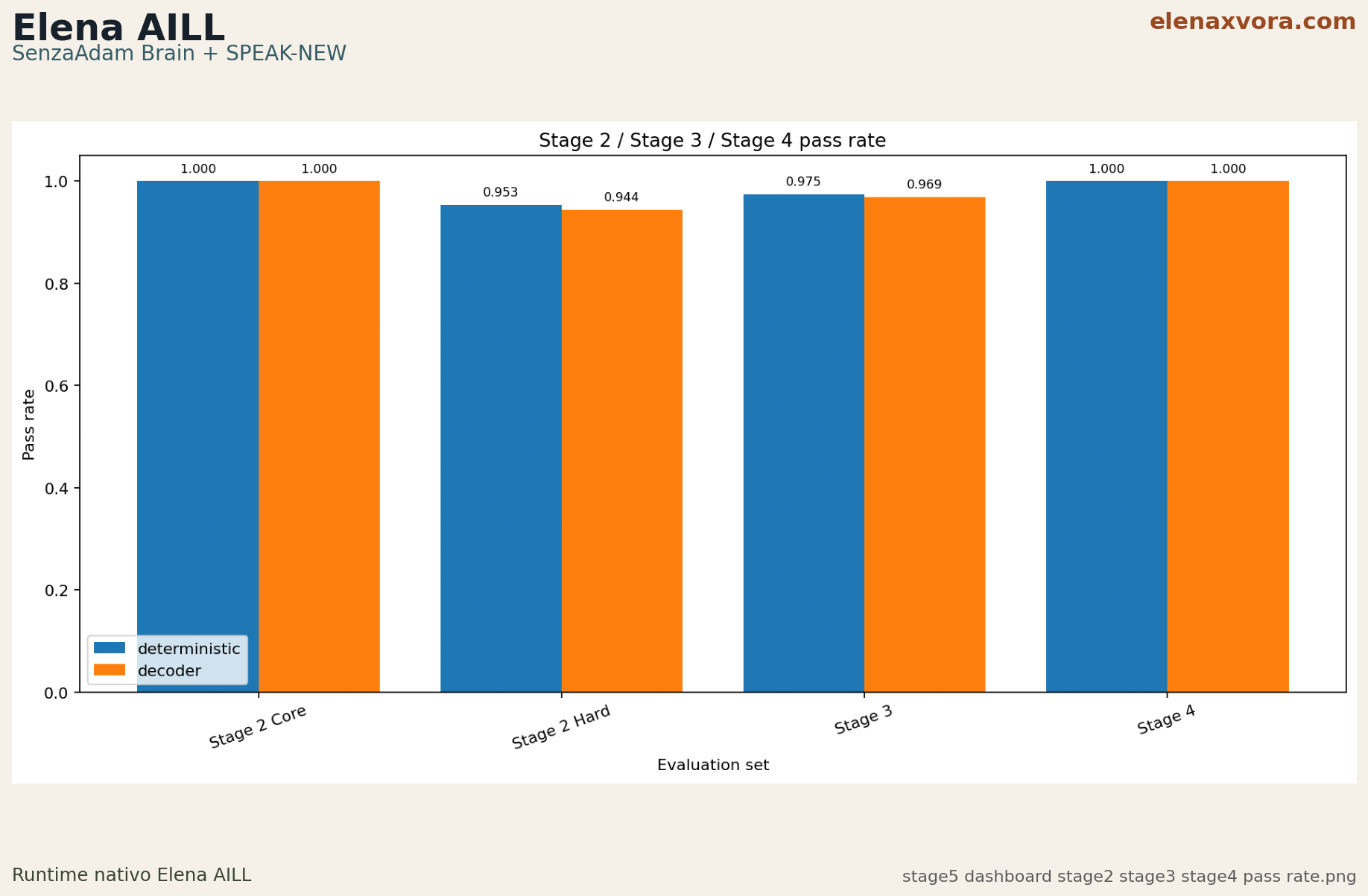
Core deterministic and decoder runs both pass, while the validated hard set keeps deterministic slightly ahead at 0.953271 versus 0.943925.
Stage 3
PASS
Deterministic pass_rate reaches 0.97493 with memory_retrieval_success at 1.0 and unknown fallback success at 1.0.
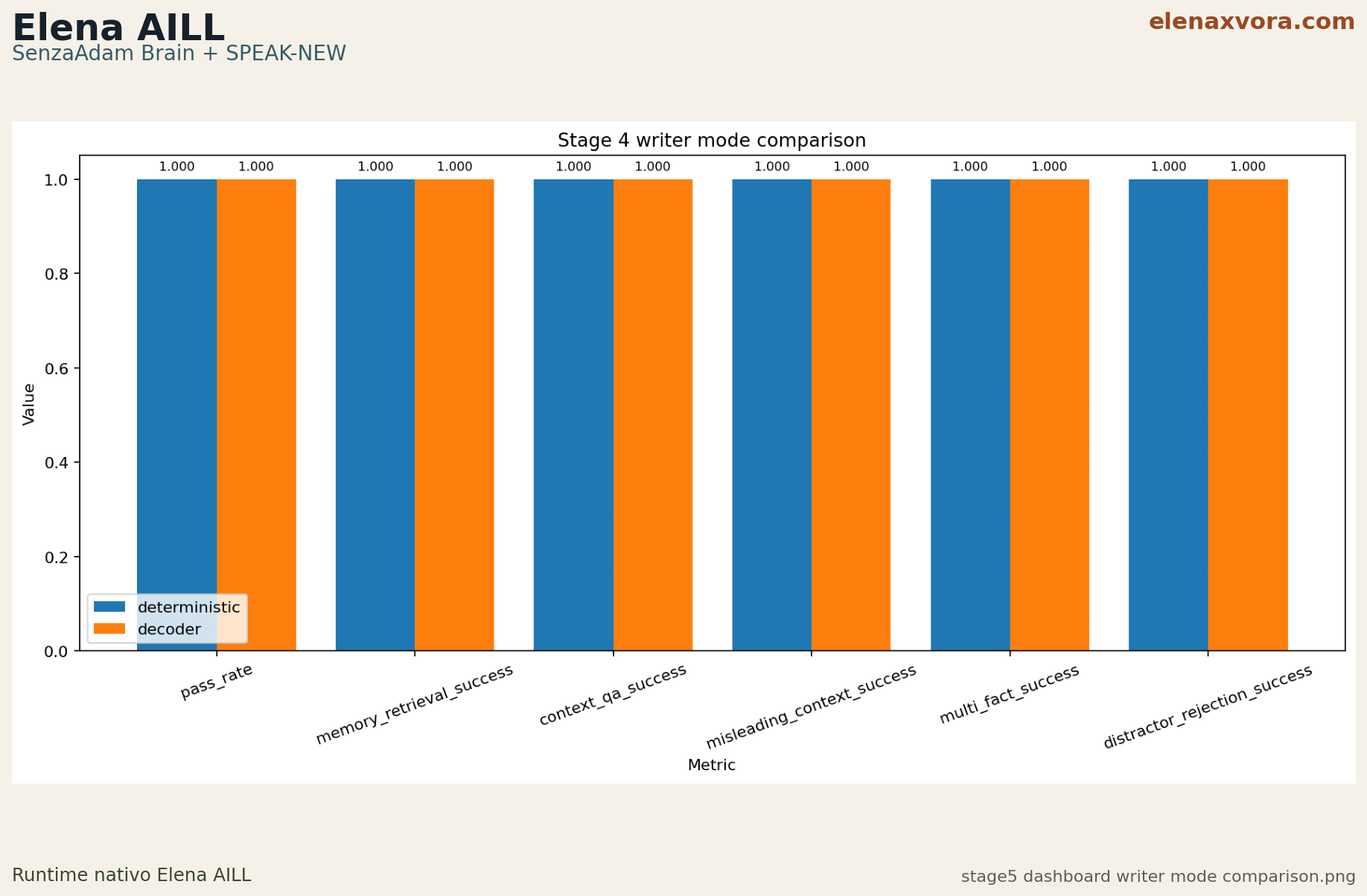
Stage 4
PASS
Deterministic and decoder both reach pass_rate 1.0 on the validated Stage 4 benchmark set.
Stage 5
PASS
Runtime evidence records the earlier SenzaAdam Brain + SPEAK-NEW Stage 5 lineage on RTX 4060 Ti with writer_mode deterministic and brain_file_size_mb 0.173. The current public formula is SenzaAdam Big Brain + Clean Speak.
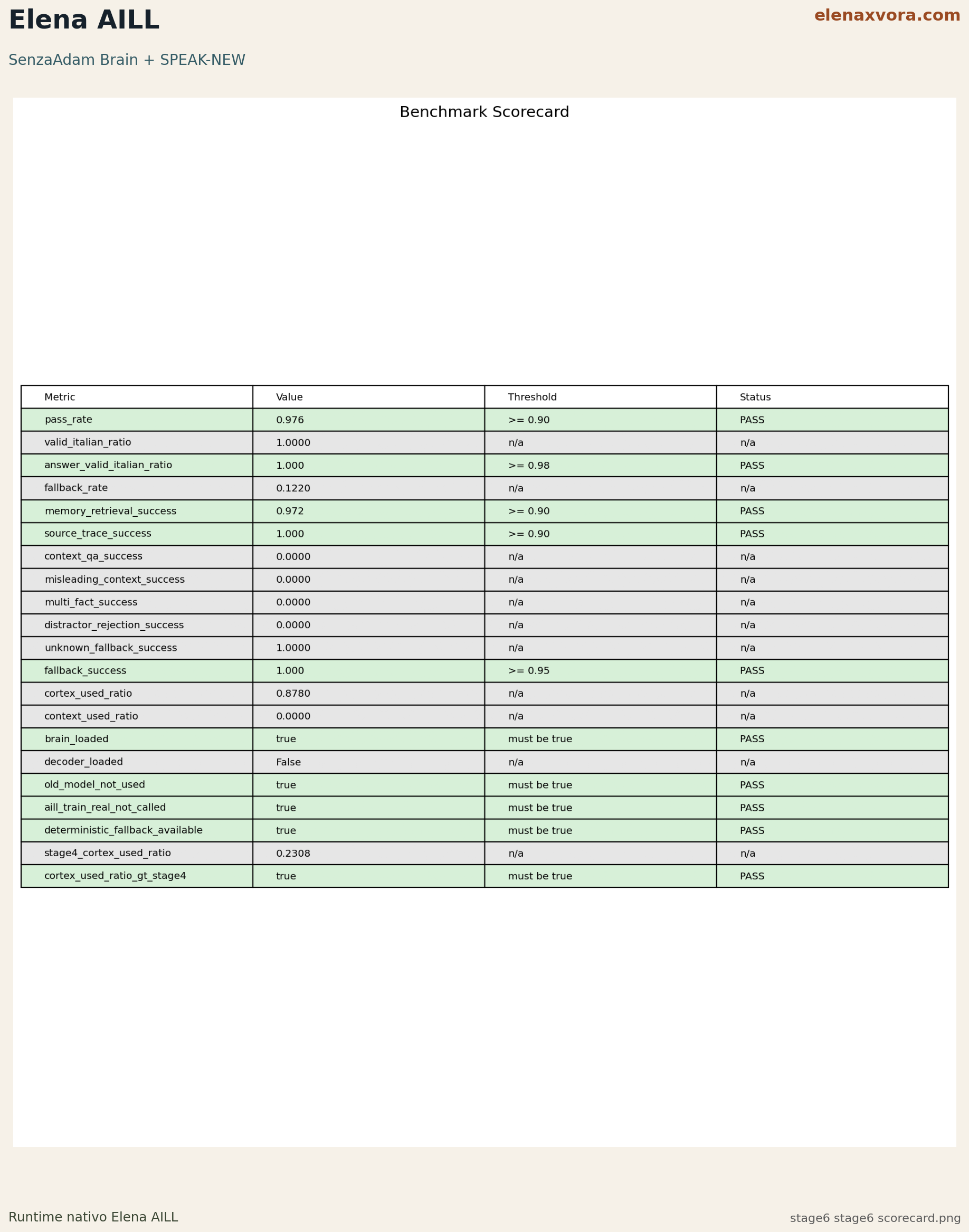
Stage 6
PASS
facts: 433, local sources: 9, mandatory selfdoc questions: 10/10, pass_rate: 0.97561, memory_retrieval_success: 0.972222, source_trace_success: 1.0, cortex_used_ratio: 0.878049.
Public scope
Research evidence only
These benchmark artifacts prove the current validated path without turning the site into a public chat product claim.
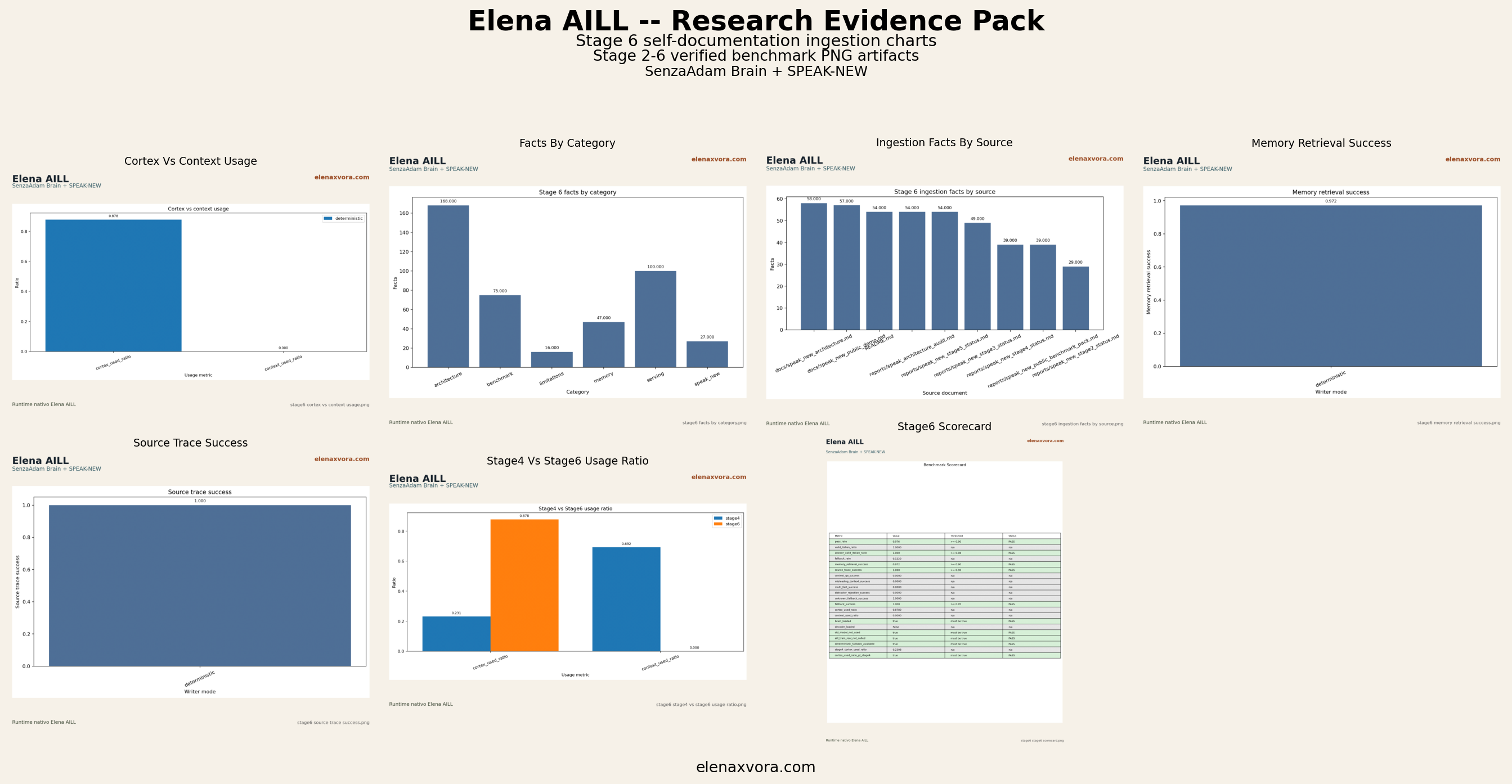
The PNG charts remain first-class public evidence because they are easy to archive, compare, and cite across updates. A visual artifact with a filename, stage label, and stable location helps readers verify that the public story is anchored to the same outputs used to build the benchmark package.
◆
This is the reference benchmark result cited in all public documentation. It supersedes the 1M suite (April 2026) which remains documented for historical completeness.
Parameter scale
| Check | Result | Notes |
|---|---|---|
| Parameter count | 10,000,000 | Stable across all checkpoints. No parameter drift observed between runs. |
| Active cells | Bounded | Cell activation stayed within design bounds throughout. No runaway growth in short or long context conditions. |
| Learning rule | Local only | Zero global backpropagation at any stage. Confirmed by code audit and training log inspection. |
| Identity anchor | Stable | Self-reference outputs consistent across 12 restart cycles and 5 different checkpoint loads. No identity drift. |
| External deps | Zero | No external LLM inference. No API calls. No borrowed weights. Network I/O during inference: none. |
| Long context | Pass | Extended context windows tested. Big Brain memory layer maintained coherence across long sessions without degradation. |
1M suite — historical reference
The 1M parameter suite was run in April 2026. Results were consistent with design expectations and established the first public evidence point. Retention was strong, active cells were bounded, and identity outputs were stable across the full run.
This suite is superseded by the 10M results for all public-facing claims. It is kept here for completeness and to document the absence of regressions between scale steps.
🔒
Demo status: private. The interactive demo is gated behind the Stage 7 quality check. Passing the 10M benchmark is a necessary condition but not sufficient on its own. Stage 7 integration must complete before demo access opens.
Public surface
What is public
Elena AILL follows an evidence-first public posture. Only validated results appear on the public surface. No speculative roadmap, no unvalidated claims, and no demo promises that cannot be immediately delivered.
Currently public
| Resource | Location | Status |
|---|---|---|
| Main website | research.elenaxvora.com ↗ | Live |
| Benchmark reports | 1M and 10M parameter validation results | Public |
| Architecture overview | Module descriptions, design rationale, constraint list | Public |
| PNG artifacts | Real benchmark output images from validated runs | Public |
Not yet public
| Resource | Gate | Status |
|---|---|---|
| Interactive demo | Stage 7 quality gate must pass first | Private |
| Source code | No release timeline set | Private |
| Model weights | No release timeline set | Private |
Positioning
Elena AILL is positioned as a research project. The public surface is designed to communicate research progress and validated evidence. Claims on the website are deliberately conservative: if something has not been validated with a reproducible run, it is not claimed.
The website at elenaxvora.com is the canonical public source of truth. This documentation exists as a more detailed companion for readers who want the full technical context behind what the website says.
Public Status
The public surface is the evidence package: benchmark summaries, real PNG artifacts, phase history, and technical documentation aligned with the repository.
Elena AILL should be described here as a system that reads, writes, handles code, and produces documents and structured outputs.
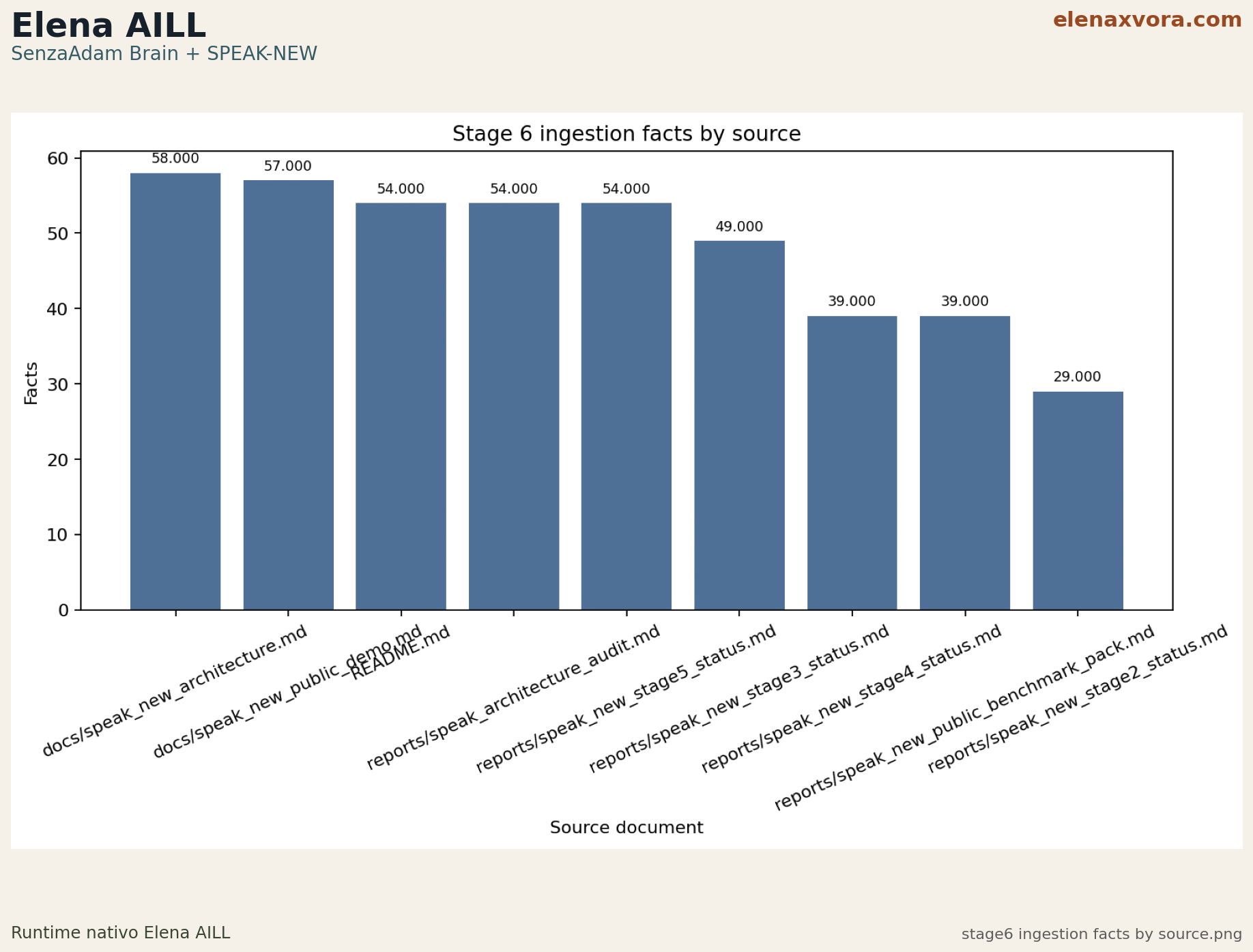
Complete PNG Inventory
Every real benchmark PNG is listed, previewed, and described in the public package. The inventory covers every real PNG in the benchmark pack plus preserved Elena AILL, GLIA, and SenzaAdam visuals already generated in the repository.
Each PNG stays tied to a stable filename, benchmark stage, and short explanation. Previews are intended to load on demand in the live site; branded PNGs are preferred for public presentation when available, while original exports remain individually accessible.
Complete PNG Inventory
Every real benchmark PNG is listed, previewed, and described.
The inventory covers every real PNG in the public benchmark package plus the preserved Elena AILL, GLIA, and SenzaAdam visuals already generated in the repository.
Each PNG stays tied to a stable filename, benchmark stage, short explanation, and reason it matters, exactly like the original public surface.
Previews load on demand. Branded PNGs are preferred for public presentation when available, while original exports remain individually accessible.
Release Scope
The current public scope is documentation, benchmark evidence, and repository-backed artifacts.
Earlier stages validated memory behavior, runtime behavior, coding, writing, and self-documentation. The remaining work is runtime integration and packaging quality, not audio positioning.
Runtime integration
Focus engineering effort on cleaner native integration around the validated SenzaAdam Big Brain + Clean Speak path instead of forcing a larger benchmark first.
Benchmark packaging
Keep the public benchmark package aligned with traceable reports, metrics summaries, and real PNG artifacts only.
Writing and code quality
Improve written output quality, code generation, and document consistency without dropping the grounded memory path that earlier validated stages already proved.
Evidence-first release
The site should present truthful evidence, reproducible benchmarks, and technical artifacts while describing Elena through the capabilities already documented here: reading, writing, code handling, documents, and structured outputs.
The site remains an evidence-first document for Elena AILL Research, SenzaAdam, and the current Applied AI validation path.
Final Public Note
Elena AILL has moved from isolated experiments to a validated persistent-memory research pipeline. GLIA remains preserved as a memory and routing research track. SenzaAdam Big Brain and Clean Speak are the current active direction. The public website shows real benchmark data, phase history, and PNG artifacts only.
The cleanest summary is this: Elena AILL remains the main research project, and the public site is an evidence layer designed to stay truthful, searchable, and conservative while reflecting what the system actually does today.